Likelihood function
The likelihood of a set of parameter values, θ, given outcomes x, is equal to the probability of those observed outcomes given those parameter values, that is
 .
.Discrete probability distribution[edit]
Let X be a random variable with a discrete probability distribution p depending on a parameter θ. Then the functionconsidered as a function of θ, is called the likelihood function (of θ, given the outcome x of X). Sometimes the probability on the value x of X for the parameter value θ is written as ; often written as
; often written as  to emphasize that this differs from
to emphasize that this differs from  which is not a conditional probability, because θ is a parameter and not a random variable.
which is not a conditional probability, because θ is a parameter and not a random variable.Continuous probability distribution[edit]
Let X be a random variable with a continuous probability distribution with density function f depending on a parameter θ. Then the functionconsidered as a function of θ, is called the likelihood function (of θ, given the outcome x of X). Sometimes the density function for the value x of X for the parameter value θ is written as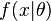 , but should not be confused with which should not be considered a conditional probability density.
, but should not be confused with which should not be considered a conditional probability density.
- The only reason to use the log-likelihood instead of the plain old likelihood is mathematical convenience, because it lets you turn multiplication into addition. The plain old likelihood is P(parameters | data), i.e. assuming your data is fixed and you vary the parameters of your model. Maximizing this is one way to do parameter estimation and is known as maximum likelihood.



No comments:
Post a Comment